.jpg)
Un directeur juridique interroge son assistant IA : "Quelle est la clause de non-concurrence dans notre contrat avec le fournisseur X ?" L'IA répond avec assurance. Clause citée, article précisé, délai mentionné. Parfait. Sauf que la clause n'existe pas. L'intelligence artificielle vient d'inventer une information plausible… et totalement fausse.
C'est une hallucination IA. Et en entreprise, ça ne pardonne pas : décision erronée, contrat non conforme, audit raté. 96 % des organisations françaises estiment que leurs données ne sont pas prêtes pour l'IA (Baromètre DSI Data & IA 2026). Pourtant, 21 % déploient quand même. Résultat : échecs, budgets perdus, confiance détruite.
La bonne nouvelle ? Les hallucinations IA ne sont pas une fatalité. Elles se produisent quand l'intelligence artificielle manque de données structurées, fiables et exploitables. Structurez vos données, et vous réduisez drastiquement les erreurs. Cet article vous explique comment.
L'essentiel à retenir
- Problème : Une hallucination IA, c'est une réponse fausse mais crédible générée par un modèle de langage. En entreprise, ça compromet la conformité et la prise de décision.
- Cause : 75 % des organisations n'ont pas sécurisé leurs fondations documentaires (Baromètre DSI Data & IA 2026) : données non structurées, absence de métadonnées, RAG mal alimenté.
- Solution : Une GED IA-ready (données structurées + métadonnées enrichies + gouvernance) améliore la précision des réponses de 30 % et réduit les hallucinations.
- Méthode Efalia : Fragmentation intelligente, base vectorielle agnostique, gouvernance centralisée, connecteurs métiers natifs. Résultat : +30 % de pertinence, +35 % de qualité sur corpus complexes.
Qu'est-ce qu'une hallucination IA et comment se produit-elle ?
Une hallucination IA, c'est quand un modèle de langage (LLM) génère une information fausse mais parfaitement plausible. L'IA répond avec assurance. Elle cite des sources, donne des chiffres, structure sa réponse. Mais c'est faux.
Pourquoi ? Parce qu'un LLM ne "sait" rien. Il prédit. Il calcule des probabilités statistiques à partir de données d'entraînement. Si la donnée fiable manque, il invente. Pas par malveillance. Par design.
Le mécanisme est simple : vous posez une question. L'IA cherche dans sa base de connaissances (ou votre base documentaire si vous utilisez un système RAG – Retrieval-Augmented Generation). Si elle ne trouve rien de pertinent, ou si les documents sont mal structurés, elle génère quand même une réponse. Statistiquement probable. Factuellement fausse.
Les chiffres parlent : selon le benchmark STARK (Wu, 2024), le taux de "Hit@1" – probabilité que la première réponse soit la bonne – plafonne à 18 % dans certains contextes. Autrement dit, dans 82 % des cas, la première réponse n'est pas fiable. Et si votre base documentaire est sale, fragmentée ou incomplète, vous tombez dans cette zone rouge.
Prenons un exemple concret. Votre agent IA doit vérifier une clause de non-concurrence. Votre base documentaire contient 500 contrats PDF non structurés. Pas de métadonnées (type de contrat, statut signé, BU concernée). Pas de plan de classement transverse. L'IA ne trouve pas la clause. Elle en invente une. Vous signez un contrat non conforme. Vous flirtez avec le risque juridique.
C'est ici que tout se joue : une IA générative n'est fiable que si elle s'appuie sur des données structurées et gouvernées.
Pourquoi les hallucinations IA posent problème en entreprise
Une clause inventée par un LLM, c'est un contrat non conforme. Un chiffre erroné dans un business plan, c'est une décision stratégique faussée. Un statut fournisseur incorrect, c'est un audit raté. Les hallucinations ne sont pas anecdotiques. Elles compromettent trois piliers de l'entreprise.
1. La conformité réglementaire
Votre IA cite une version obsolète d'une procédure qualité ISO. L'auditeur la relève. Vous perdez votre certification. Ou pire : votre agent IA indique qu'un document RGPD est conforme alors qu'il manque des mentions obligatoires. Vous êtes en infraction.
Le problème : 85 % des organisations ne contrôlent pas la qualité de leurs données documentaires de manière régulière (Baromètre DSI Data & IA 2026). 29 % n'ont aucun contrôle, 56 % font du nettoyage ponctuel. Résultat : versions multiples, statuts flous, dates de validité inconnues. L'IA ne sait pas quelle version est la bonne. Elle devine. Et elle se trompe.
2. La prise de décision
Un directeur général demande une synthèse sur un projet stratégique. L'IA agrège des documents de tous les services. Sauf qu'elle mélange un brouillon de business plan (non validé) avec un compte rendu de comité de direction (validé). Le DG prend une décision sur la base de données erronées.
La réalité du terrain : 53 % des DSI citent "mauvaise qualité des résultats" comme risque principal de l'IA (Baromètre DSI Data & IA 2026). Ce n'est pas un risque théorique. C'est une réalité quotidienne pour plus de la moitié des organisations qui déploient de l'IA.
3. La confiance métier et le Shadow IT
47 % des organisations obtiennent un score de 0 ou 1 sur 5 en préparation face au Shadow IT IA (Baromètre DSI Data & IA 2026). Autrement dit, elles ne maîtrisent pas ce que leurs collaborateurs font avec des outils IA externes (ChatGPT, Gemini, Claude). Résultat : hallucinations fréquentes, erreurs répétées, rejet de l'IA par les métiers.
Un juriste qui obtient trois fois une réponse fausse arrête d'utiliser l'agent IA. Il retourne à ses mails. Vous avez perdu l'adoption. Bon courage pour relancer un projet IA après ça.
18 % des organisations ne savent pas où sont localisées leurs données IA (Baromètre DSI Data & IA 2026). Difficile de contrôler les hallucinations quand on ne sait même pas où sont les données qui les alimentent.
Les 3 causes principales des hallucinations IA
Trois causes expliquent les hallucinations. Bonne nouvelle : deux sont entièrement sous votre contrôle. Mauvaise nouvelle : 75 % des entreprises ne les maîtrisent pas.
Cause 1 : Données non structurées ou sales
Le constat du Baromètre DSI Data & IA 2026 est sans appel :
- 75 % des organisations n'ont pas sécurisé leurs fondations documentaires (cycle de vie initial ou émergent)
- 57 % classent encore manuellement leurs documents
- 85 % ne maîtrisent pas la qualité de leur patrimoine documentaire (aucun contrôle ou nettoyage ponctuel)
- 56 % n'ont pas dépassé la recherche basique (recherche manuelle ou moteur basique)
Concrètement, ça veut dire quoi ? Des doublons (Dupont SA / DUPONT / Dupont SAS = trois entrées différentes pour le même fournisseur). Des métadonnées manquantes (type de document inconnu, date de validité absente, statut flou). Des documents scannés non indexés (PDF image sans OCR). Des versions multiples sans indication de laquelle est valide.
Résultat : l'IA ne sait pas quelle source est fiable. Elle mélange brouillon et version signée. Elle cite un document obsolète. Elle invente pour combler les trous.
Cause 2 : Absence de contexte fiable (RAG mal alimenté)
Vous avez peut-être déployé un système RAG (Retrieval-Augmented Generation). C'est le mécanisme qui permet à une IA de consulter VOS documents avant de répondre, au lieu de se fier uniquement à sa mémoire d'entraînement. C'est comme donner un manuel à un expert plutôt que de lui demander de se rappeler ce qu'il a lu il y a deux ans.
Mais un RAG ne fonctionne que s'il est alimenté par des données structurées et gouvernées. Problème : seuls 13 % des organisations utilisent un chatbot ou un RAG (Baromètre DSI Data & IA 2026). Et parmi elles, combien ont réellement sécurisé leurs fondations documentaires ? Très peu.
Quatre problèmes concrets rendent un RAG inefficace :
- Fragmentation inadaptée : Vos documents PDF sont découpés en blocs de 500 caractères sans logique sémantique. L'IA récupère des fragments hors contexte. Elle reconstitue une réponse à partir de morceaux incohérents. Une mauvaise fragmentation peut faire chuter le taux de pertinence en dessous de 20 % (Wu, 2024).
- Absence de métadonnées exploitables : L'IA ne peut pas filtrer par BU, par date de validité, par statut signé/brouillon. Elle traite tout à égalité. Le brouillon de contrat a autant de poids que la version signée. Elle hallucine sur la base de documents obsolètes ou non validés.
- SharePoint : gouvernance distribuée : SharePoint fonctionne bien pour la collaboration, mais pas pour un RAG d'entreprise. Chaque espace peut avoir ses propres règles, ses propres métadonnées. Pas de plan de classement transverse imposé. Pas de traçabilité unifiée. Résultat : l'IA mélange les versions, ignore les droits, cite des documents non valides.
- Absence de gouvernance IA : 24 % des organisations n'ont mis en place aucun élément de gouvernance IA (Baromètre DSI Data & IA 2026). Pas de politique, pas de traçabilité, pas de registre de cas d'usage. L'IA accède à tout, sans filtre, sans contrôle. Vous flirtez avec le risque de fuite de données et d'hallucinations incontrôlées.

Cause 3 : Limites intrinsèques du modèle
Certains modèles hallucinent plus que d'autres. C'est un fait. Mais cette cause est non contrôlable par l'entreprise. Vous ne pouvez pas réécrire GPT-4 ou Claude. En revanche, vous pouvez structurer vos données pour que n'importe quel modèle – même imparfait – fonctionne mieux.
Focus action : Causes 1 et 2 sont sous votre contrôle. Structurez vos données, enrichissez vos métadonnées, fragmentez intelligemment vos documents, posez un cadre de gouvernance minimal. Vous réduisez drastiquement les hallucinations, quel que soit le modèle utilisé.
Comment prévenir les hallucinations avec une GED IA-ready
La solution n'est pas de changer de modèle IA. C'est de structurer vos données pour que n'importe quel modèle puisse les exploiter sans inventer. Une GED connectée à l'IA repose sur 5 piliers techniques qui, ensemble, réduisent drastiquement les hallucinations.
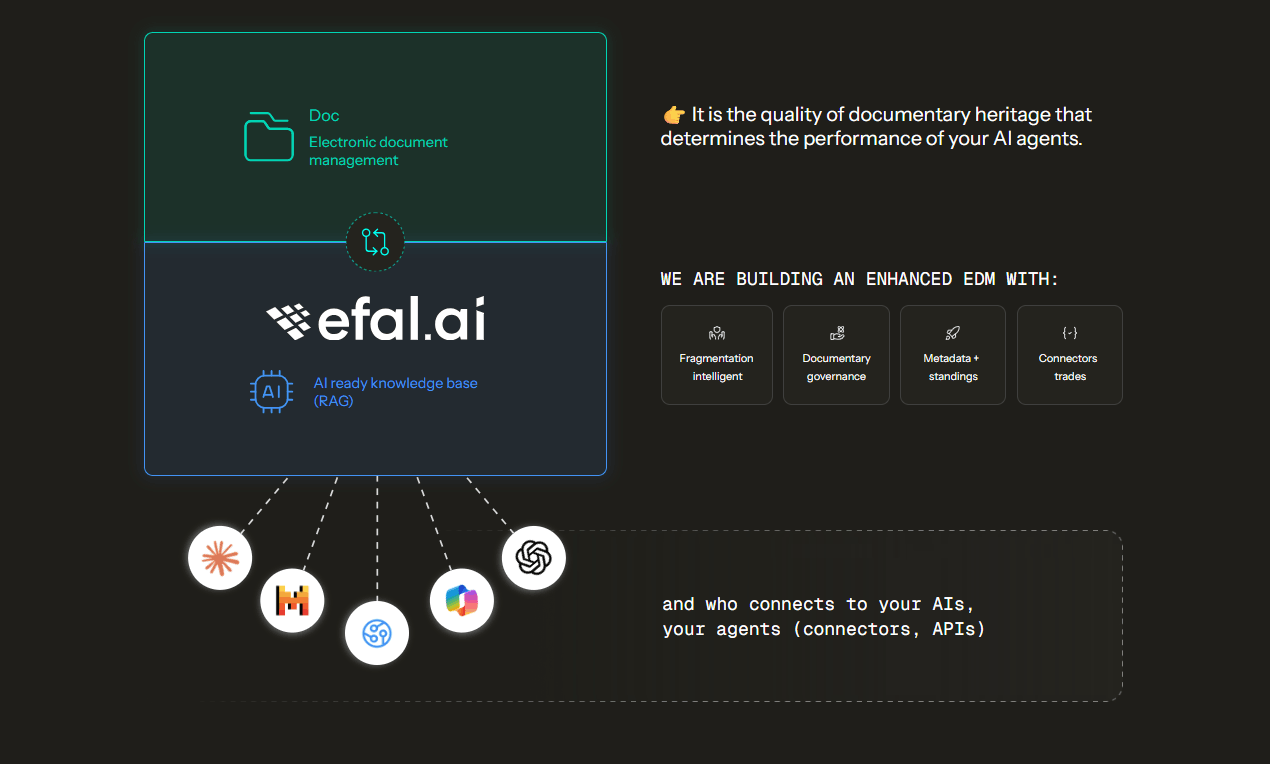
Pilier 1 : Fragmentation contextuelle
Comment ça prévient les hallucinations ? Vos documents sont découpés en blocs sémantiques cohérents (pas en morceaux brutaux de 500 caractères). Un contrat est fragmenté par clause. Une procédure qualité par étape. Un compte rendu par décision. L'IA récupère le bon contexte, pas un fragment hors-sol.
L'impact : Une mauvaise fragmentation fait chuter la pertinence en dessous de 20 % (Wu, 2024). Une fragmentation contextuelle garantit que chaque réponse s'appuie sur un bloc de sens complet. Résultat : -40 % de latence, réponses précises sans hallucination.
Pilier 2 : Gouvernance documentaire renforcée
Comment ça prévient les hallucinations ? L'IA ne doit jamais répondre à partir d'un document obsolète, non validé ou destiné à un autre service. La gouvernance impose : gestion fine des droits (utilisateur, groupe, rôle), traçabilité complète des consultations, politique de cycle de vie (statuts, alertes d'échéance, archivage conforme), conformité RGPD et ISO 27001.
L'impact : Un juriste qui interroge l'IA sur un contrat confidentiel ne verra que les documents auxquels il a accès. L'IA filtre automatiquement par droits. Pas de fuite. Pas de réponse basée sur un brouillon non validé. Vous respectez la conformité.
Pilier 3 : Métadonnées et plan de classement transverse
Comment ça prévient les hallucinations ? Les métadonnées sont la grammaire de l'IA. Elles permettent de filtrer les résultats selon des critères objectifs (type de document, BU, date de validité, statut signé/brouillon), de hiérarchiser les sources (version signée > brouillon), de limiter les hallucinations grâce au contexte.
L'impact : Un enrichissement en métadonnées améliore la précision des réponses de 30 % (de 53 % à 83 % de pertinence, Earley 2023). Métadonnées enrichies + requêtes hybrides = +35 % de qualité sur corpus complexes (Jing, 2024). L'IA sait quelle version est valide. Elle ne devine plus.
Le problème SharePoint : SharePoint fonctionne en gouvernance distribuée. Chaque équipe a ses métadonnées, ses règles, ses structures. Pas de plan transverse. Pas de traçabilité unifiée. L'IA hallucine, mélange les versions, ignore les droits. Une GED transverse impose un plan de classement unique. L'IA accède à une vision cohérente de l'entreprise.
Pilier 4 : Interopérabilité et connecteurs métiers
Comment ça prévient les hallucinations ? Vos documents sont versés automatiquement depuis vos outils métiers (bulletins de paie depuis SIRH, factures depuis ERP, contrats depuis CRM). Ils arrivent avec leurs métadonnées enrichies, leurs droits synchronisés, leur statut validé. L'IA accède à une base actualisée, gouvernée, transverse.
L'impact : Fini les documents dispersés entre SharePoint, disques partagés et messageries. L'IA interroge une source unique de vérité. Les droits sont synchronisés avec l'annuaire d'entreprise. Chaque document a son contexte métier. Vous éliminez les hallucinations liées aux données obsolètes ou non vérifiées.
Pilier 5 : Base vectorielle agnostique
Comment ça prévient les hallucinations ? Vos documents sont transformés en représentations mathématiques (vecteurs) stockées dans une base de données IA agnostique. Vous testez GPT, Claude, Mistral, Llama sans refonte. Si un modèle hallucine trop, vous switchz en 48 heures. Vous gardez vos données en France (hébergement SecNumCloud). Vous évitez l'enfermement technologique.
L'impact : Vous ne dépendez d'aucun fournisseur IA. Votre base de connaissances reste exploitable à long terme. Si GPT-5 est meilleur que GPT-4, vous l'intégrez sans perdre vos données. Vous maîtrisez la chaîne de bout en bout.
Le constat du baromètre : 29 % des DSI citent "dépendance fournisseur" comme risque. Seuls 5 % utilisent une plateforme souveraine. Le discours sur la souveraineté ne se traduit pas encore dans les pratiques. Une base vectorielle agnostique vous protège.
Checklist : 5 fondations pour limiter les hallucinations
☐ Fragmentation contextuelle (blocs sémantiques, pas découpage brutal)
☐ Gouvernance documentaire (droits, traçabilité, cycle de vie, conformité)
☐ Métadonnées + plan de classement transverse (grammaire de l'IA, +30 % précision)
☐ Connecteurs métiers (versement auto, enrichissement à la volée, droits synchronisés)
☐ Base vectorielle agnostique (indépendance, souveraineté, éviter vendor lock-in)
Conclusion : des données propres = une IA fiable
L'IA n'est pas magique. Elle n'invente pas par malveillance. Elle prédit à partir de ce que vous lui donnez. Si vous injectez du bordel dans la base de connaissances, vous aurez du bordel indexé. Et des hallucinations.
La bonne nouvelle : vous contrôlez deux des trois causes principales des hallucinations. Structurez vos données. Enrichissez vos métadonnées. Fragmentez intelligemment vos documents. Posez un cadre de gouvernance minimal (2 éléments suffisent pour devenir accélérateur). Vous réduisez drastiquement les erreurs. Vous passez de 53 % à 83 % de pertinence (Earley, 2023). Vous gagnez +35 % de qualité sur des corpus complexes (Jing, 2024).
Le diagnostic des DSI français est clair (Baromètre DSI Data & IA 2026) : 68 % placent "gouvernance et qualité des données" comme priorité n°1 pour 2026. Ils ne se trompent pas. La Data avant l'IA. Sans fondations documentaires solides, l'intelligence artificielle hallucine.
L'enjeu de 2026 : transformer votre gestion électronique de documents de simple outil de classement en fondation stratégique de votre intelligence artificielle d'entreprise. Les entreprises qui structurent aujourd'hui prennent un avantage concurrentiel durable. Les autres hallucinent.
👉 Découvrez comment Efalia transforme votre GED en base de connaissances IA-ready : GED connectée à l'IA



.jpg)
.png)