
L’Intelligence Artificielle ne fonctionne en entreprise que si elle s’appuie sur des données structurées et gouvernées. Pourtant, la majorité des projets RAG (Retrieval-Augmented Generation) échouent par manque de fondations documentaires solides.
Dans ce guide pratique, découvrez les 5 piliers techniques indispensables pour transformer votre gestion électronique de documents en moteur d’intelligence artificielle d’entreprise.
Pourquoi la RAG ne fonctionne pas (encore) en entreprise
Les défis techniques sous-estimés
Selon Earley (2023), l’un des principaux malentendus dans les projets IA est de croire que les LLM éliminent le besoin d’architecture documentaire. Les tests expérimentaux montrent qu’un enrichissement en métadonnées (amélioration de la recherche documentaire) augmente la précision des réponses de 30% (de 53% à 83% de pertinence).
Comme le souligne Jeong (2023), un système RAG ne se limite pas à coller une base vectorielle à un modèle IA. Il faut orchestrer plusieurs briques : fragmentation documentaire, génération d’embeddings, vectorisation, bases de données spécialisées, prompt engineering, filtrage par droits utilisateurs…
Des performances encore instables
Même les systèmes les plus avancés, testés sur des benchmarks comme STARK (Wu, 2024), montrent des limites. Le taux de “Hit@1” – probabilité que la première réponse soit la bonne – plafonne à 18% dans certains contextes.
Le problème de gouvernance
La majorité des entreprises n’a pas les fondations pour maîtriser ce qu’elle donne à ses IA, notamment en l’absence d’un workflow automatisé qui assure la dématérialisation des flux et la classification intelligente des documents.
Les 5 piliers d’une gestion documentaire intelligente
✅ Pilier 1 : Fragmentation et vectorisation intelligente
Le défi de la fragmentation sémantique
Transformer des documents non structurés (PDF, Word, mails) en blocs d’information compréhensibles par une IA nécessite un découpage sémantique précis – le “chunking”.
Impact sur les performances
Une mauvaise fragmentation peut nuire à la qualité des réponses IA. Selon Wu (2024), les performances des moteurs RAG dépendent fortement de la qualité du découpage initial : un mauvais chunking peut faire chuter le taux de “Hit@1” en dessous de 20%.
L’expertise Efalia en fragmentation intelligente
Chez Efalia, nous avons développé des moteurs de fragmentation contextuelle qui s’appuient sur la structure documentaire existante : titres, métadonnées, champs métiers. Le tout, facilité par la reconnaissance optique des caractères, nativement présent dans la GED. Cette approche permet une fragmentation sémantique, pas seulement technique, optimisant ainsi la qualité des embeddings pour votre base vectorielle.
✅ Pilier 2 : Gouvernance documentaire renforcée
Les exigences de sécurité
Une IA ne devrait jamais répondre à partir d’un document obsolète, non validé ou destiné à un autre service. La gouvernance de l’information implique :
- Gestion fine des droits (utilisateur, groupe, rôle) notamment pour la sécurité des données GED.
- Traçabilité complète des consultations et modifications – optimisation des processus documentaires
- Politique de cycle de vie des documents – optimisation archivage
- Conformité RGPD, ISO 27001 – conformité réglementaire de la GED
GED vs Sharepoint : Pourquoi SharePoint n’est pas suffisant
SharePoint fonctionne bien pour la collaboration mais présente des limites pour la RAG :
- Gouvernance distribuée : chaque espace peut avoir ses propres règles
- Pas de plan de classement transverse imposé
- Métadonnées non standardisées entre équipes
- Manque de traçabilité unifiée sur l’ensemble de l’organisation
✅ Pilier 3 : Métadonnées et plan de classement unifié
Les métadonnées comme grammaire de l’IA
Les métadonnées ne sont pas un “plus” documentaire mais la grammaire que l’IA va utiliser pour comprendre ce qu’elle lit. Elles permettent de :
- Filtrer les résultats selon des critères objectifs –> performance documentaire
- Hiérarchiser les sources (version signée > brouillon)
- Limiter les hallucinations grâce au contexte
L’importance du plan de classement
Le plan de classement agit comme une cartographie logique de votre entreprise. Dans un système RAG, cela permet à l’IA de cibler précisément les blocs d’information utiles.
L’approche Efalia pour les métadonnées intelligentes
Notre Content Service Platform intègre nativement une logique de métadonnées métiers. Contrairement aux solutions généralistes, nous proposons :
- Templates métiers pré-configurés : ressources humaines, qualité, finance avec champs normalisés
- Plan de classement évolutif : adapté à votre organisation, modifiable en autonomie avec classification automatique en GED
- Cycle de vie automatisé : statuts, alertes d’échéance, archivage conforme
Cette structuration native prépare vos contenus pour l’intelligence artificielle sans disruption de vos processus métiers.
✅ Pilier 4 : Interopérabilité et connecteurs métiers
Connecter la gestion électronique de documents à l’entreprise réelle
Une plateforme documentaire isolée devient un nouveau silo. L’agent conversationnel a besoin d’un accès transversal, contrôlé et actualisé à l’information distribuée dans votre écosystème logiciel.
Les connecteurs essentiels
- Versement automatique depuis vos outils métiers (bulletins de paie depuis SIRH) – extraction de données
- Enrichissement à la volée (classification automatique en GED depuis les outils métiers)
- Synchronisation des droits avec l’annuaire d’entreprise
- Exposition via API pour alimenter agents IA et Copilots : intelligence artificielle GED
L’expertise connecteurs d’Efalia
Fort de notre expérience avec +2800 clients, nous avons développé des connecteurs natifs avec les principaux outils métiers :
- SIRH : e.sedit de Berger Levrault, HR Access de Sopra HR…
- ERP/Finance : SAP, Sage,…
Notre approche API-first garantit une interopérabilité durable et évite les développements spécifiques coûteux. Chaque connecteur respecte automatiquement les règles de gouvernance définies dans la GED.
✅ Pilier 5 : Base vectorielle agnostique
Garder le contrôle technologique
La base vectorielle stocke les représentations mathématiques (embeddings) de vos documents. Une base agnostique garantit :
- Indépendance vis-à-vis d’un LLM spécifique
- Interrogation par API sans solution propriétaire
- Respect des règles d’accès (filtrage par rôles, services)
- Contrôle total (hébergement, structure, sécurité)
La vision Efalia : base vectorielle souveraine
Nous croyons à une IA d’entreprise souveraine et maîtrisée.
Notre approche intègre une base vectorielle agnostique qui vous permet de :
- Tester tous les modèles : GPT, Claude, Mistral, Llama sans refonte
- Garder vos données en France : hébergement SecNumCloud
- Maintenir la gouvernance : filtrage automatique par droits métiers
- Éviter le vendor lock-in : indépendance technologique garantie
Cette architecture vous prépare aux évolutions IA futures tout en conservant le contrôle total de votre patrimoine documentaire.
Impact sur la performance
Dans une étude de Jing et al. (2024), la combinaison métadonnées enrichies + requêtes hybrides améliore de 35% la qualité des réponses sur des corpus complexes.
Découvrez les benchmarks détaillés et les comparatifs techniques dans notre guide complet.
Investissement et planning pour votre projet
Budget et délais réalistes
Construire une base documentaire prête pour la RAG demande entre 3 et 6 mois selon la maturité initiale. Budget estimé : 30 000 à 100 000 euros selon la volumétrie et complexité métier.
Phases projet recommandées
- Audit de l’existant (fichiers, GED, SharePoint, messagerie)
- Définition du plan de classement et métadonnées critiques
- Choix et mise en œuvre du moteur GED/base vectorielle
- Traitement technique des documents (nettoyage, structuration)
- Intégration aux outils métiers et tests de sécurité
Cette base technique permet de multiplier les cas d’usage IA sans tout reconstruire : tester différents LLM, créer plusieurs agents métiers, connecter Microsoft Copilot… sans perdre le contrôle sur la donnée source.
L’approche Efalia : GED nativement IA-ready
Efalia structure et gouverne la documentation d’entreprise depuis 1982. Cette expertise en gestion documentaire nous positionne aujourd’hui comme l’acteur idéal pour préparer vos données à l’Intelligence Artificielle : nous transformons votre GED en source de vérité structurée, gouvernée et exploitable par l’intelligence artificielle.
Notre approche : de la Gestion Électronique de Documents à la base de connaissance IA
Notre métier historique – structurer, sécuriser et interconnecter les documents – devient aujourd’hui la fondation critique pour une IA d’entreprise fiable et le traitement intelligent des documents. Nous ne faisons pas de l’IA, nous préparons vos données pour qu’elle fonctionne.
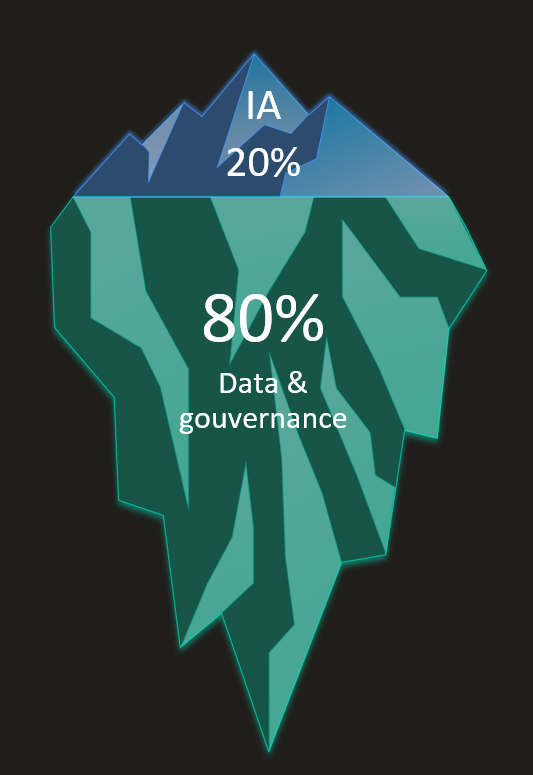
Notre différenciation technique
- Architecture API-first : interopérabilité totale avec votre écosystème
- Fragmentation contextuelle : moteurs de découpage sémantique propriétaires
- Gouvernance centralisée : gestion fine par rôles, métiers et niveaux de confidentialité
- Base vectorielle agnostique : testez tous les modèles IA sans refonte
- Connecteurs métiers natifs : +45 partenaires technologiques
Notre engagement souveraineté
- Hébergement SecNumCloud : données en France, certifiées ANSSI
- Code source maîtrisé : pas de dépendance technologique externe
- Conformité native : RGPD, ISO 27001, réglementations sectorielles
Conclusion : 5 points clés à retenir
- La qualité des contenus détermine la performance IA. En complément, l’usage du machine learning GED permet d’optimiser l’extraction automatisée d’informations et de renforcer la pertinence des résultats, contribuant ainsi à une édition intelligente des documents : sans structuration documentaire, pas de RAG fiable.
- Les métadonnées sont la grammaire de l’Intelligence Artificielle: elles améliorent de 30% la précision des réponses
- SharePoint n’est pas adapté à la RAG d’entreprise : gouvernance distribuée et manque de standardisation
- L’interopérabilité est critique : une GED isolée ne peut pas alimenter l’IA métier
- L’indépendance technologique protège vos investissements : base vectorielle agnostique pour tester tous les modèles
L’enjeu de 2025 : transformer votre Gestion Électronique de Documents de simple outil de classement en fondation stratégique de votre intelligence artificielle d’entreprise.
? Prêt à structurer votre GED pour l’IA ?
Sources citées :
- Earley (2023) – Architecture documentaire et LLM
- Jeong (2023) – Complexité d’intégration des systèmes RAG
- Wu et al. (2024) – Benchmark STARK, NeurIPS
- Jing et al. (2024) – When Large Language Models Meet Vector Databases: A Survey, arXiv




